
フィールド解決順序の操作
Multiple Query Execution が提供する @export ディレクティブの目的は、フィールド(またはフィールドの集合)の値を変数にエクスポートし、クエリ内の別の場所で使用することです。
変数への値のエクスポートが行われる前に変数の読み取りが行われると、このディレクティブは機能しません。そのため、エンジンはフィールドの実行順序を制御する方法を提供する必要があります。
Gato GraphQL は、クエリ自体を通じてフィールドの実行順序を操作する方法を提供しています。エンジンは各タイプごとにイテレーションでデータを読み込みます。まずクエリ内で最初に遭遇したタイプのすべてのフィールドを解決し、次に2番目のタイプのすべてのフィールドを解決するという順序で、処理すべきタイプがなくなるまで続きます。
例えば、Director、Film、Actor タイプのオブジェクトが関係する次のクエリを見てみましょう:
{
directors {
name
films {
title
actors {
name
}
}
}
}...は GraphQL エンジンによって次の順序で解決されます:

処理済みのタイプが、未読み込みのデータ(例:追加オブジェクト、または既に読み込まれたオブジェクトの追加フィールド)を取得するためにクエリ内で再び参照された場合、そのタイプはイテレーションリストの末尾に再度追加されます。
例えば、Actor の preferredDirector フィールド(Director タイプのオブジェクトを返します)も次のようにクエリする場合:
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}...GraphQL エンジンはクエリを次の順序で処理します:

1つのクエリで @export を実行する場合にこれがどのように機能するかを見てみましょう。最初の試みとして、フィールドの実行順序を考慮せず、通常どおりクエリを作成します:
query GetPostsAuthorNames {
user(by: { id: 1 }) {
name @export(as: "authorName")
}
posts(filter: { search: $authorName }) {
id
title
}
}クエリを実行すると、次のレスポンスが返されます:
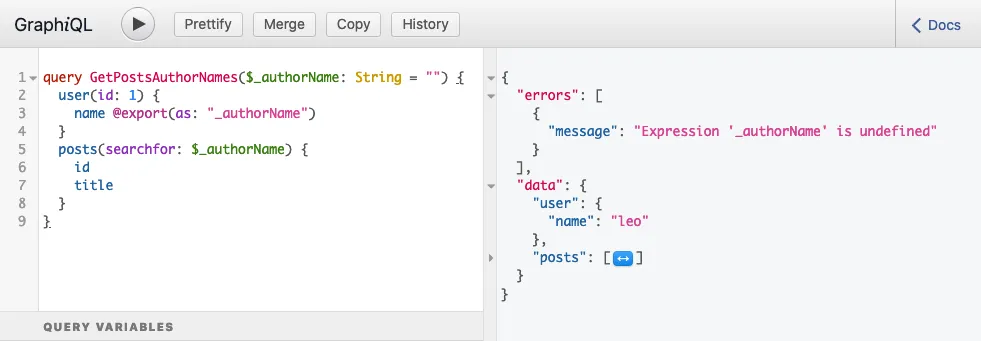
...次のエラーが含まれています:
{
"errors": [
{
"message": "Expression 'authorName' is undefined",
}
]
}このエラーは、変数 $authorName が読み取られた時点でまだ設定されておらず、undefined であったことを意味します。
なぜこれが起こるのかを見てみましょう。まず、クエリに登場するタイプを以下のコメントとして分析します:
# Type: Root
query GetPostsAuthorNames {
# Type: User
user(by: {id: 1}) {
# Type: String
name @export(as: "authorName")
}
# Type: Post
posts(filter: { search: $authorName }) {
# Type: ID
id
# Type: String
title
}
}タイプを処理してデータを読み込むために、データ読み込みエンジンはクエリタイプ Root を FIFO(First-In, First-Out:先入れ先出し)リストに追加します。これによりアルゴリズムに渡される初期リストは [Root] となり、その後タイプを順次イテレーションします:
| # | 操作 | リスト |
|---|---|---|
| 0 | FIFOリストを準備する | [Root] |
| 1a | リストの最初のタイプ(Root)を取り出す | [] |
| 1b | Root タイプからクエリされたすべてのフィールドを処理する:→ user(by: {id: 1})→ posts(filter: { search: $authorName })それらのタイプ( User と Post)をリストに追加する | [User, Post] |
| 2a | リストの最初のタイプ(User)を取り出す | [Post] |
| 2b | User タイプからクエリされたフィールドを処理する:→ name @export(as: "authorName")スカラー型( String)なので、リストに追加する必要はない | [Post] |
| 3a | リストの最初のタイプ(Post)を取り出す | [] |
| 3b | Post タイプからクエリされたすべてのフィールドを処理する:→ id→ titleスカラー型( ID と String)なので、リストに追加する必要はない | [] |
| 4 | リストが空になり、イテレーションが終了する。 |
ここで問題が明らかになります:@export はステップ 2b で実行されますが、読み取りはステップ 1b で行われていました。
ここでフィールドの実行フローを制御する必要があります。実装された解決策は、エクスポートされた変数が読み取られるタイミングを遅らせることで、Root タイプから self フィールドを人工的にクエリすることで実現されます。
self フィールドは、その名前が示すとおり、同じオブジェクトを返します。Root オブジェクトに適用すると、同じ Root オブジェクトを返します。「すでにルートオブジェクトを持っているのに、なぜ再度取得する必要があるのか?」と思うかもしれません。なぜなら、エンジンのアルゴリズムがこの新しい Root への参照を FIFO リストの末尾に追加する必要があり、それによってクエリされたフィールドをこれらの各イテレーションの前後に意図的に分配できるからです。
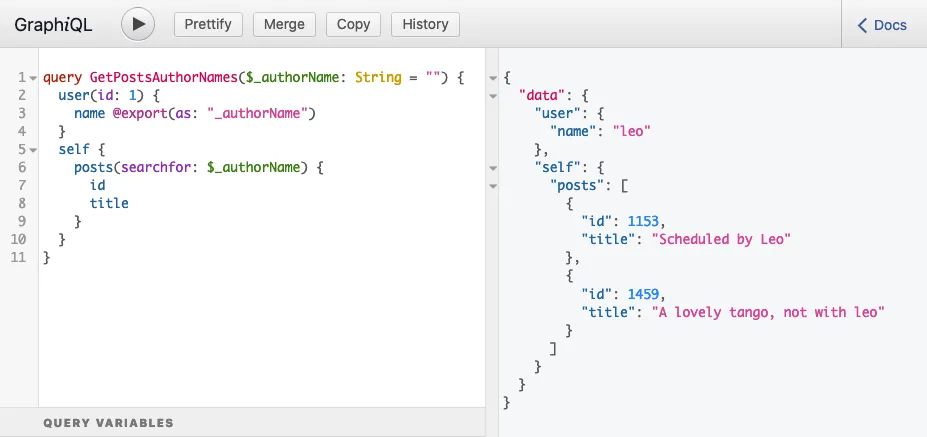
そのため、上記のクエリでは posts(filter:{ search: $authorName }) フィールドが self フィールドの内側に配置されており、クエリを実行すると期待どおりのレスポンスが返されます:
query GetPostsAuthorNames {
user(by: {id: 1}) {
name @export(as: "authorName")
}
self {
posts(filter: { search: $authorName }) {
id
title
}
}
}
このクエリでタイプが処理される順序を確認し、なぜうまく機能するのかを理解しましょう:
| # | 操作 | リスト |
|---|---|---|
| 0 | FIFOリストを準備する | [Root] |
| 1a | リストの最初のタイプ(Root)を取り出す | [] |
| 1b | Root タイプからクエリされたすべてのフィールドを処理する:→ user(by: {id: 1})→ selfそれらのタイプ( User と Root)をリストに追加する | [User, Root] |
| 2a | リストの最初のタイプ(User)を取り出す | [Root] |
| 2b | User タイプからクエリされたフィールドを処理する:→ name @export(as: "authorName")スカラー型( String)なので、リストに追加する必要はない | [Root] |
| 3a | リストの最初のタイプ(Root)を取り出す | [] |
| 3b | Root タイプからクエリされたフィールドを処理する:→ posts(filter:{ search: $authorName })そのタイプ( Post)をリストに追加する | [Post] |
| 4a | リストの最初のタイプ(Post)を取り出す | [] |
| 4b | Post タイプからクエリされたすべてのフィールドを処理する:→ id→ titleスカラー型( ID と String)なので、リストに追加する必要はない | [] |
| 5 | リストが空になり、イテレーションが終了する。 |
これで問題が解決されたことがわかります:@export はステップ 2b で実行され、ステップ 3b で読み取られます。
Multiple Query Execution は クエリの分離 を行う際にまさにこれを実行します:GraphQL ドキュメントを変換して self フィールドを追加することで、各オペレーションのフィールドが前のすべてのオペレーションのすべてのフィールドが解決された後にのみ実行されるようにします。