
データローディングエンジン
Gato GraphQL はサーバーサイドコンポーネントを使用してデータモデルを表現します(グラフやツリーではありません)。GraphQL クエリを解決するためにデータロードプロセスがどのように実行されるかを見ていきましょう。
データを処理するためには、コンポーネントを型にフラット化し(<FeaturedDirector> => Director、<Film> => Film、<Actor> => Actor)、コンポーネント階層に現れた順に並べ(Director、次に Film、次に Actor)、「イテレーション」単位で処理します。各イテレーションで各型のオブジェクトデータを取得します。

サーバーのデータローディングエンジンは、データをロードするために以下の(擬似)アルゴリズムを実装する必要があります。
準備:
- データベースから取得する必要があるオブジェクトのIDリストを格納するための空のキューを用意します。型ごとに整理します(各エントリは
[型 => IDのリスト]の形式になります) - フィーチャードディレクタオブジェクトのIDを取得し、型
Directorとしてキューに追加します
キューにエントリがなくなるまでループ:
- キューの先頭エントリ(型とIDのリスト、例:
Directorと[2])を取得し、そのエントリをキューから削除します - 型の
TypeDataLoaderオブジェクトを使用して、データベースに対して1回のクエリを実行し、該当するIDを持つすべてのオブジェクトを取得します - 型にリレーショナルフィールドがある場合(例: 型
Directorには型Filmのリレーショナルフィールドfilmsがある)、現在のイテレーションで取得したすべてのオブジェクトからそれらのフィールドのすべてのIDを収集し(例: 型Directorのすべてのオブジェクトのフィールドfilmsにある全ID)、該当する型としてキューに追加します(例: IDの[3, 8]を型Filmとして)。
イテレーションが終了すると、すべての型のすべてのオブジェクトデータがロードされています。
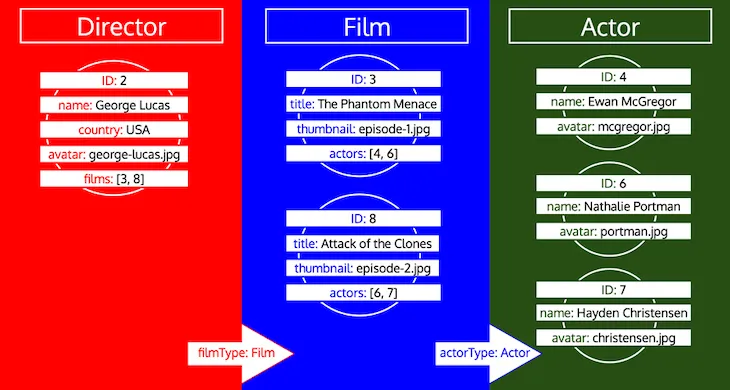
型のすべてのIDは、その型がキューで処理されるまで収集される点に注意してください。たとえば、型 Director にリレーショナルフィールド preferredActors を追加した場合、これらのIDは型 Actor としてキューに追加され、型 Film のフィールド actors からのIDと一緒に処理されます。
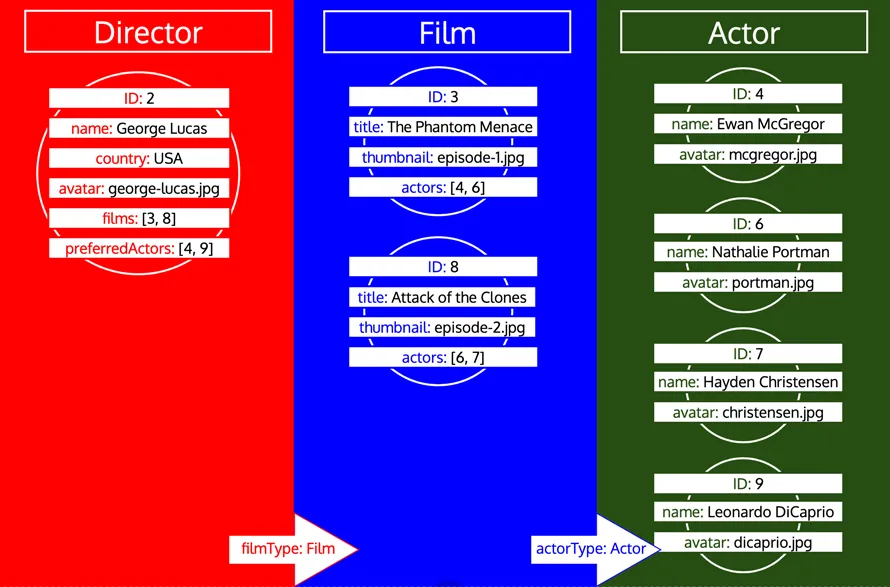
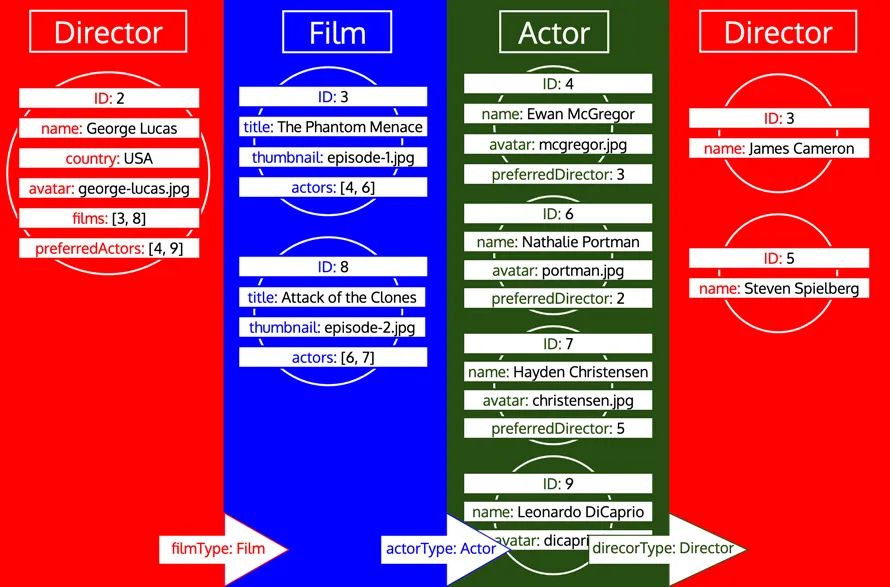
ただし、ある型が処理済みであっても、その型からさらにデータをロードする必要がある場合は、その型に対して新しいイテレーションが行われます。たとえば、Author 型にリレーショナルフィールド preferredDirector を追加すると、型 Director が再びキューに追加されます。
すべてのオブジェクトデータを取得したので、GraphQL クエリを反映した期待されるレスポンスの形に整形する必要があります。しかし、見て分かるように、データには必要なツリー構造がありません。代わりに、リレーショナルフィールドにはネストされたオブジェクトへのIDが含まれており、リレーショナルデータベースでのデータ表現を模倣しています。したがって、この比較に従うと、各型について取得したデータは次のようにテーブルとして表現できます。
型 Director のテーブル:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
型 Film のテーブル:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
型 Actor のテーブル:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
すべてのデータがテーブルとして整理され、各型が互いにどのように関連しているか(つまり、Director はフィールド films を通じて Film を参照し、Film はフィールド actors を通じて Actor を参照する)がわかれば、GraphQL サーバーはデータを期待されるツリー形式に簡単に変換できます。
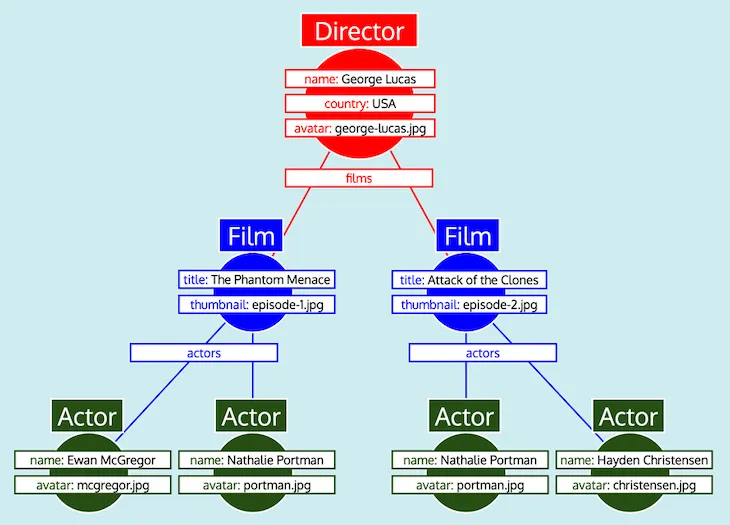
最後に、GraphQL サーバーはツリーを出力します。これは期待されるレスポンスの形を持っています。
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}ソリューションの時間計算量の分析
データロードアルゴリズムのビッグO記法を分析して、入力数が増えるにつれてデータベースに対して実行されるクエリ数がどのように増加するかを理解し、このソリューションが高いパフォーマンスを発揮することを確認しましょう。
データローディングエンジンは、各型に対応するイテレーションでデータをロードします。イテレーションを開始する時点では、取得すべきすべてのオブジェクトのすべてのIDのリストがすでに揃っているため、対応するオブジェクトのすべてのデータを取得するために1回のクエリを実行できます。これにより、データベースへのクエリ数は、クエリに含まれる型の数に対して線形に増加することがわかります。言い換えると、時間計算量は O(n) であり、n はクエリ内の型の数です(ただし、ある型が複数回イテレーションされる場合は、n に複数回加算されます)。
このソリューションは非常に高いパフォーマンスを発揮し、グラフを扱う場合に予想される指数的な計算量や、ツリーを扱う場合に予想される対数的な計算量よりもはるかに優れています。
実装された PHP コード
データロードプロセスは、パッケージ Component Model のクラス Engine の関数 getComponentData で行われます。