
ディレクティブパイプライン
ディレクティブはパイプラインに配置され、順番に実行されます。その初期設計はシンプルで、次のようになっています。

このアーキテクチャでは:
- パイプラインへの入力は、フィールドリゾルバーが提供するフィールドの値です
- 各ディレクティブはロジックを実行し、結果をパイプライン内の次のディレクティブに渡します
- パイプラインの出力は、すべてのディレクティブによって処理された後の解決済みフィールド値になります
ただし、このアーキテクチャはGraphQLの能力を最大限に活かしているとは言えません。以下では、実際のディレクティブパイプラインのすべてのステージを、Gato GraphQLで実際に実装されている設計に至るまで説明します。
クエリ解決のビルディングブロックとしてのディレクティブ
最初は、GraphQLサーバーが何らかのメカニズムでフィールドを解決し、その値をディレクティブパイプラインへの入力として渡すことを考えるかもしれません。
しかし、すべてを処理する単一のメカニズムを持つ方がはるかにシンプルです。フィールドリゾルバーの呼び出し(フィールドの検証とフィールドの解決の両方)は、すでにディレクティブパイプラインを通じて行うことができます。この場合、ディレクティブパイプラインがクエリを解決するための唯一のメカニズムとなります。
このため、Gato GraphQLサーバーには2つの特別なディレクティブが用意されています。
@validateはフィールドリゾルバーを呼び出して、フィールドが解決できるかどうかを検証します(例:構文が正しい、フィールドが存在する、など)- 検証が成功した場合、
@resolveValueAndMergeがフィールドリゾルバーを呼び出してフィールドを解決し、その値をレスポンスオブジェクトにマージします
これら2つは特別なタイプの「システム」ディレクティブです。GraphQLエンジンのみに予約されており、すべてのフィールドで暗黙的に使用されます。(対照的に、標準のディレクティブは明示的です。ユーザーがクエリに追加します。)
これら2つのディレクティブを使用することで、次のクエリ:
query {
field1
field2 @directiveA
}...は次のように解決されます:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}パイプラインは次のようになります(パイプラインがフィールドを入力として受け取り、初期解決値ではないことに注意してください):

パイプラインスロット
ディレクティブは通常@resolveValueAndMergeの後に実行されます。これは、解決済みフィールドの値を更新することが多いためです。ただし、@validateの前、または@validateと@resolveValueAndMergeの間に実行する必要があるディレクティブも存在します。
例えば:
- フィールドの解決にかかる時間を計測するために、ディレクティブ
@traceExecutionTimeはパイプラインの先頭にサブディレクティブ@startTracingExecutionTimeを、末尾に@endTracingExecutionTimeを配置することで、フィールドが解決される前後の現在時刻を取得できます - ディレクティブ
@cacheは、@resolveValueAndMergeを実行する前に、要求されたフィールドがキャッシュされているかどうかを確認し、すでにキャッシュされている場合はそのレスポンスを返す必要があります
パイプラインはクラスPipelinePositionsを通じて5つの異なるスロットを提供し、ディレクティブはどのスロットで実行されるかを指定します。
"beginning"スロット:最初の位置"before-validate"スロット:検証が行われる前"middle"スロット:検証後、フィールド解決前"after-resolve"スロット:フィールド解決後"end"スロット:最後の位置
ディレクティブパイプラインは次のようになります(簡略化のため3つのステージのみを考慮):

このアーキテクチャでは、ディレクティブ@skipと@includeがいかに簡単に実現できるかに注目してください。"middle"スロットに配置されることで、フラグskipExecutionをtrueに設定することにより、ディレクティブ@resolveValueAndMerge(およびパイプライン内の後続ステージのすべてのディレクティブ)に実行しないよう通知できます。
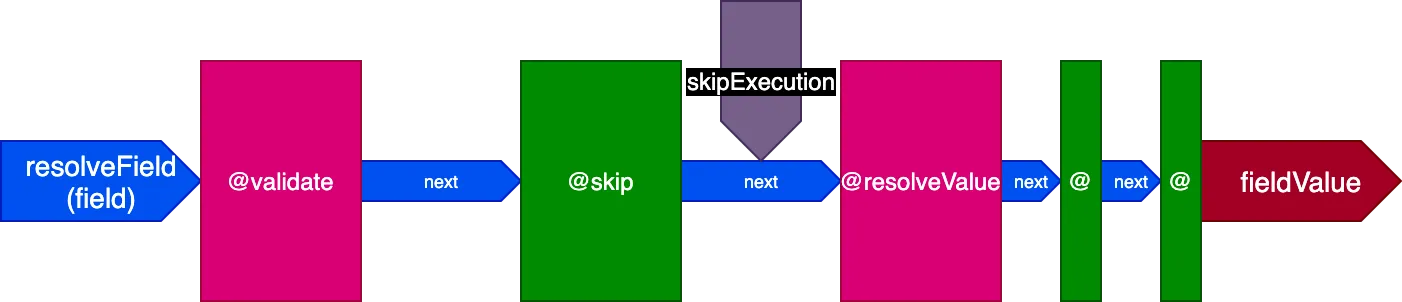
単一の呼び出しで複数のフィールドにディレクティブを実行する
これまでは、ディレクティブパイプラインへの入力として単一のフィールドを考えてきました。しかし、典型的なGraphQLクエリでは、ディレクティブを実行する複数のフィールドを受け取ります。
例えば、以下のクエリでは、ディレクティブ@upperCaseがフィールド"field1"と"field2"に対して実行されます。
query {
field1 @upperCase
field2 @upperCase
field3
}さらに、GraphQLエンジンはクエリのすべてのフィールドにシステムディレクティブ@validateと@resolveValueAndMergeを追加するため、次のクエリ:
query {
field1
field2
field3
}...は次のクエリとして解決されます:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}そのため、システムディレクティブは常にすべてのフィールドを入力として受け取ります。
その結果、ディレクティブパイプラインは、一度に1つではなく、複数のフィールドを入力として受け取るように設計されています。

このアーキテクチャはより効率的です。すべてのフィールドに対してディレクティブを1回だけ実行する方が、フィールドごとに1回ずつ実行するよりも高速であり、同じ結果を生成するからです。
例えば、スキーマへのアクセスを許可するためにユーザーがログインしているかどうかを検証する場合、その操作は1回だけ実行できます。次のコードを実行することは:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}このコードを実行するよりも効率的です:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}isUserLoggedInのようなローカル関数を呼び出す場合は大きな差ではないかもしれませんが、GraphQLを通じてRESTエンドポイントを解決するなど、外部サービスと連携する場合は大きな違いが生まれます。このような場合、関数を複数回ではなく1回だけ実行することが、特定の機能を提供できるかどうかの差を生むことがあります。
例を見てみましょう。@translateディレクティブを通じてGoogle Translateと連携する場合、GraphQL APIはネットワーク経由で接続を確立する必要があります。次のコードを実行するのが最も高速です:
googleTranslateFields([$field1, $field2, $field3]);対照的に、関数を個別に複数回実行すると、より高いレイテンシが発生し、APIのパフォーマンスが低下します。3つの文字列を翻訳する場合(フィールドが翻訳する文字列)は大きな差ではないかもしれませんが、100以上の文字列の場合は確実に影響があります:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);さらに、すべての入力を一度に関数に渡すことで、各フィールドを個別に関数で処理するよりも優れたレスポンスが得られる場合があります。再びGoogle Translateを例にとると、サービスに提供するデータが多いほど、翻訳はより正確になります。
例えば、以下のコードを実行すると:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");最初の個別実行では、Googleは"fork"のコンテキストを知らないため、食事用フォーク、道路の分岐、または別の意味として返答する可能性があります。しかし、代わりに次のように実行すると:
googleTranslate(["fork", "road", "sign"]);この広い情報量から、Googleは"fork"が道路の分岐を指していることを推測し、正確な翻訳を返すことができます。
これらの理由から、パイプライン内のディレクティブは入力フィールドをすべてまとめて受け取り、各ディレクティブはこれらの入力に対してロジックを実行する最善の方法を決定できます(入力ごとに1回の実行、すべての入力を含む1回の実行、またはその間の任意の方法)。
パイプラインは次のようになります:
クエリ全体に対して単一のディレクティブパイプラインを実行する
先ほど、ディレクティブごとに複数のフィールドを実行することが理にかなっていることを学びました。ただし、これはすべてのフィールドに同じディレクティブが適用されている場合にうまく機能します。ディレクティブが異なる場合、実装を難しくする複雑さが増し、得られた利点の一部が失われる可能性があります。
これがどのように起こるか見てみましょう。次のクエリを考えます:
query {
field1 @directiveA
field2
field3
}このディレクティブは次と同等です:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}このシナリオでは、フィールドfield2とfield3が同じディレクティブセットを持ち、field1が異なるセットを持つため、クエリを解決するために2つの異なるパイプラインを生成する必要があります:
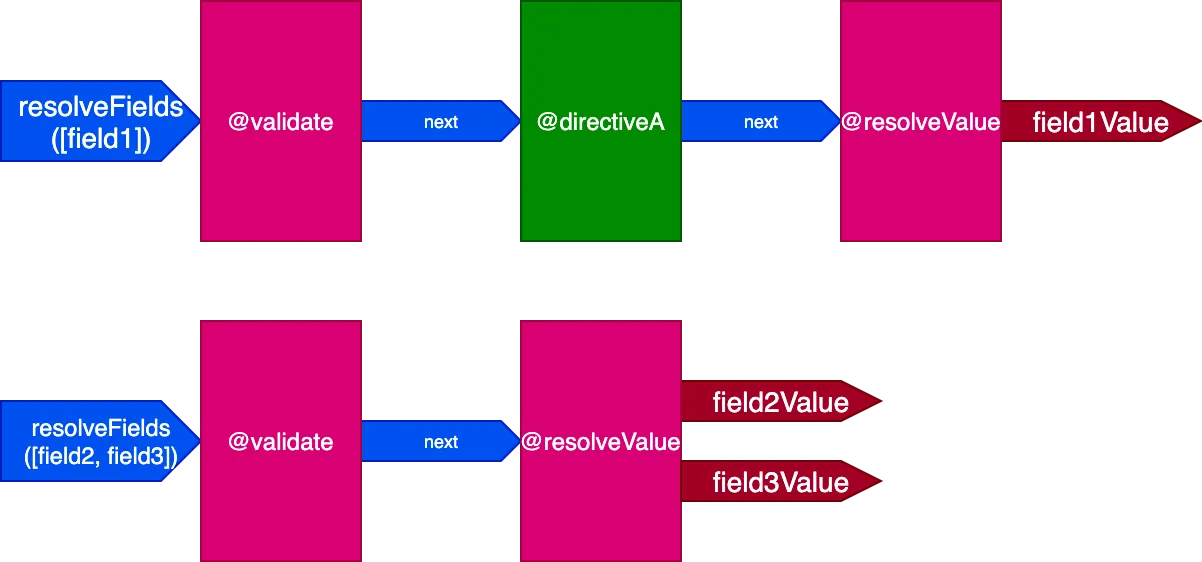
すべてのフィールドが一意のディレクティブセットを持つ場合、効果はさらに顕著になります。このクエリを考えます:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}これは次と同等です:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}この状況では、3つのフィールドを処理するために3つのパイプラインが必要になります:
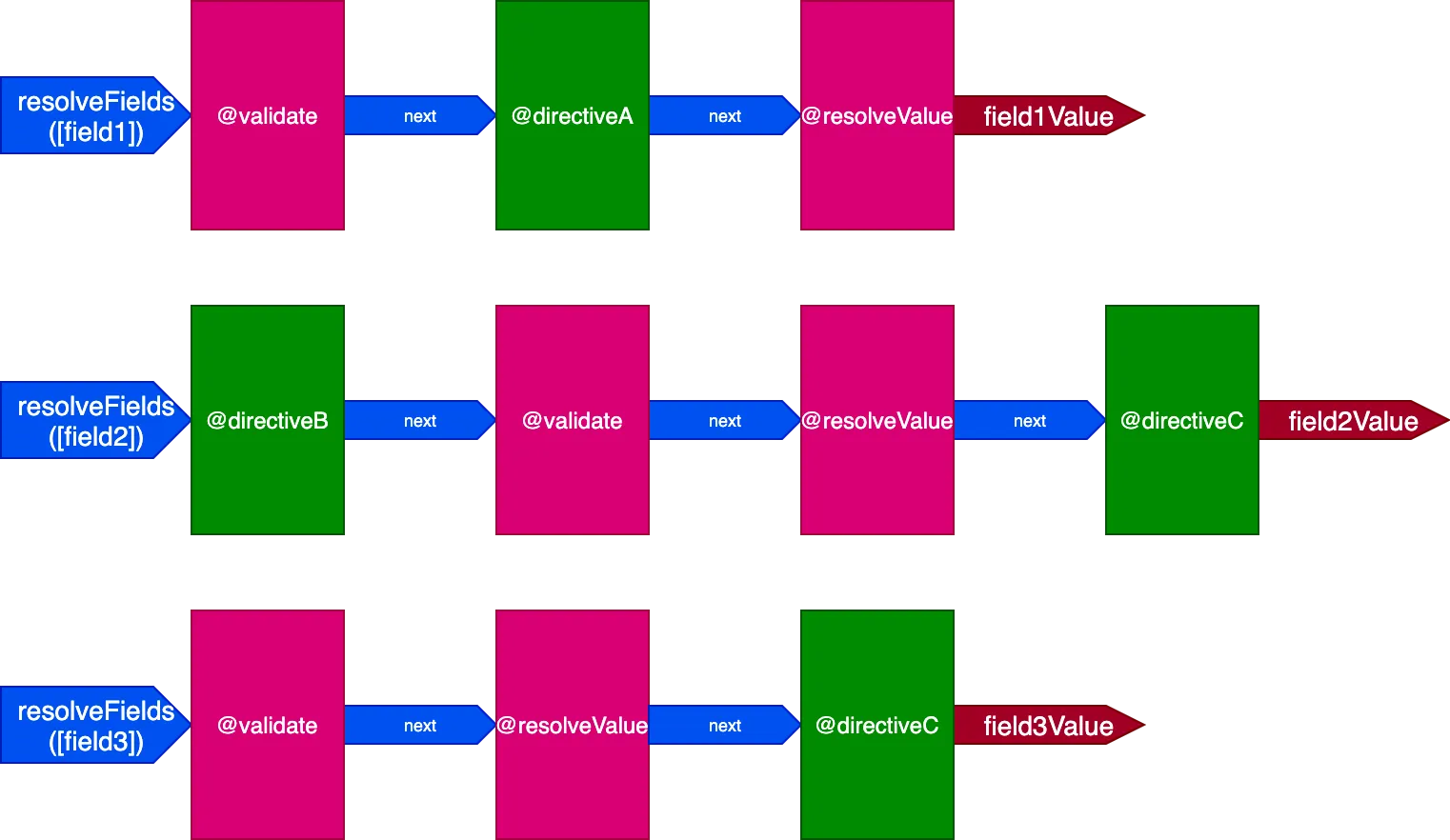
この場合、ディレクティブ@validateと@resolveValueAndMergeは3つのフィールドすべてに適用されていますが、3つの異なるディレクティブパイプラインを通じて実行されるため、互いに独立して実行されます。これにより、ディレクティブが一度に単一のアイテムに対して実行される状況に戻ってしまいます。
この問題の解決策は、複数のパイプラインを生成することを避け、すべてのフィールドに対して単一のパイプラインで処理することです。その結果、エンジンはフィールドをパイプラインへの入力として渡さなくなります。単一のパイプライン内のすべてのディレクティブが同じフィールドセットと連携するわけではないためです。代わりに、各ディレクティブは自分自身の入力として独自のフィールドリストを受け取る必要があります。
次のクエリでは:
query {
field1 @directiveA
field2
field3
}...ディレクティブ@validateと@resolveValueAndMergeは3つのフィールドすべてを入力として受け取り、directiveAは"field1"のみを受け取ります:
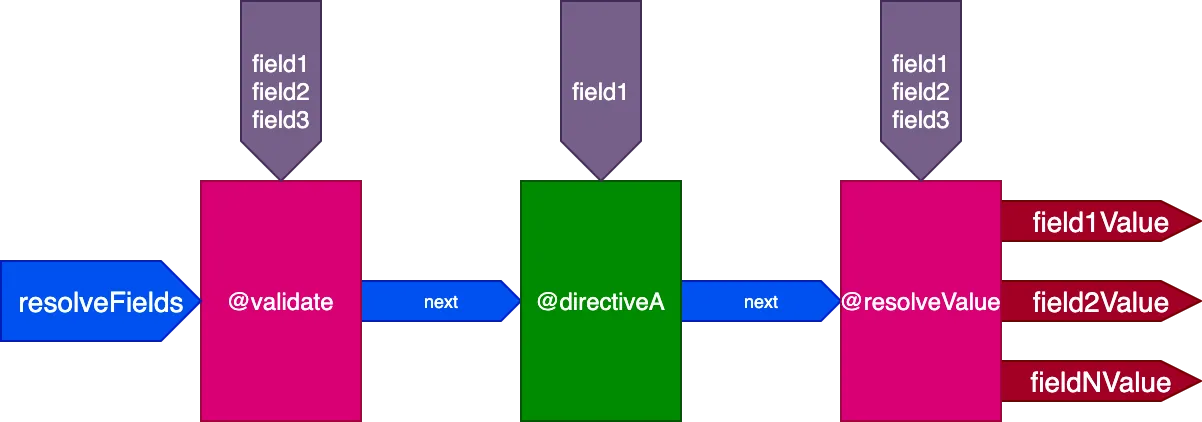
このクエリでは:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...ディレクティブ@validateと@resolveValueAndMergeは3つのフィールドすべてを入力として受け取り、directiveAは"field1"のみを、directiveBは"field2"のみを、directiveCは"field2"と"field3"を受け取ります:
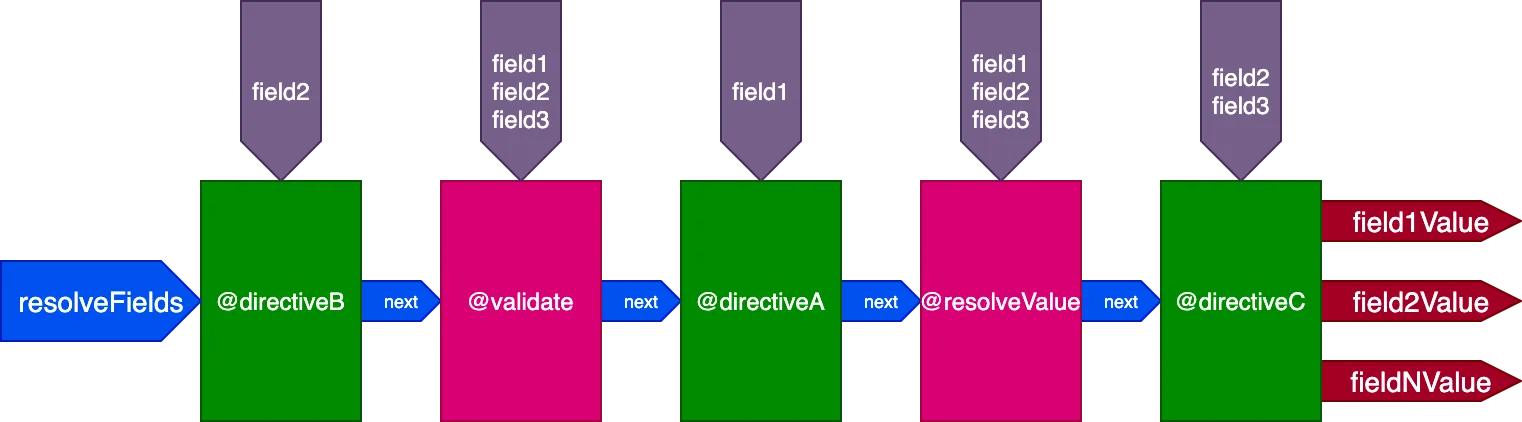
IDごとにディレクティブの実行を制御する
これまで、あるステージのディレクティブは、フラグskipExecutionを通じて後のステージのディレクティブの実行に影響を与えることができました。しかし、このフラグはすべてのケースに対して十分に細かい制御ができません。
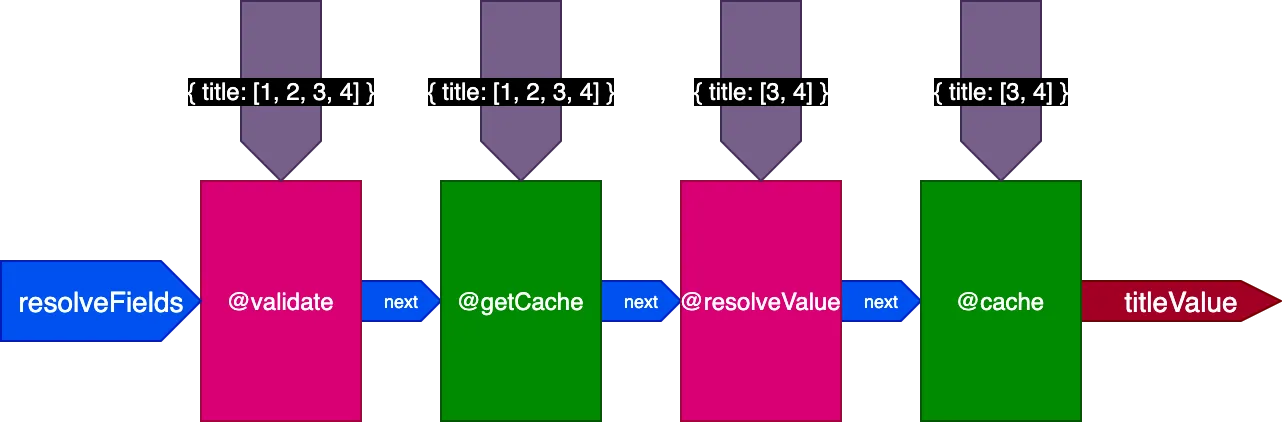
例えば、"end"スロットに配置されてフィールド値を保存するディレクティブ@cacheを考えてみましょう。次回フィールドがクエリされた際、"middle"スロットに配置されたディレクティブ@getCacheを通じてキャッシュからその値を取得できます:
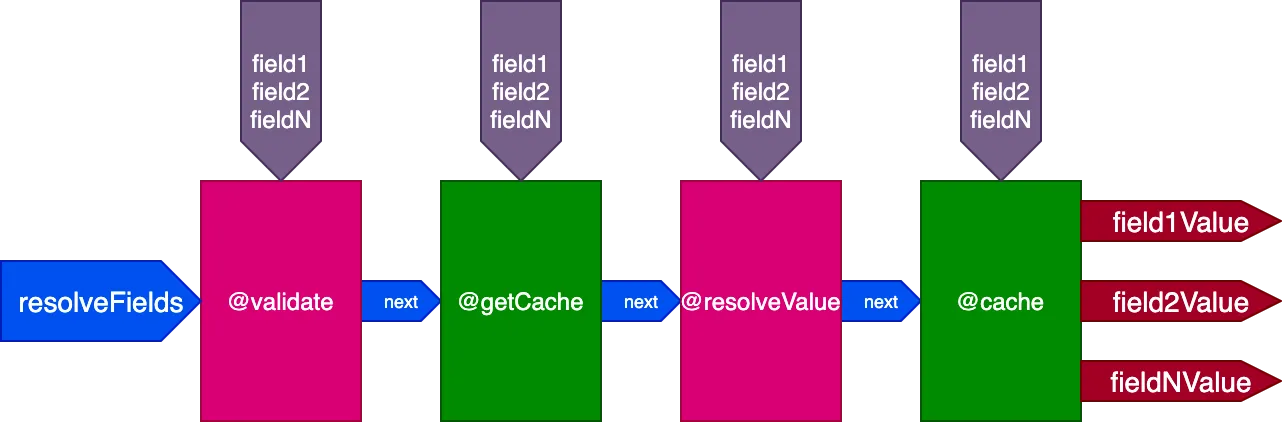
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}サーバーは2件のレコードを取得してキャッシュします。次に、同じクエリを4件のレコードに適用して実行します:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}この2回目のクエリを実行する際、最初のクエリの2件のレコードはすでにキャッシュされていますが、残りの2件はキャッシュされていません。しかし、フラグskipExecutionを使用するためには、4件のレコードすべてがすでにキャッシュされている必要があります。最初の2件のレコードをキャッシュから取得し、残りの2件のレコードのみを解決できれば、より良いでしょう。
そこで、パイプラインの設計を再度更新します。フラグskipExecutionを廃止し、代わりに入力オブジェクトfieldIDsを通じて、ディレクティブを適用すべきフィールドごとのオブジェクトIDのリストを各ディレクティブに渡します:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}変数fieldIDsは各ディレクティブに固有であり、すべてのディレクティブが後のステージのすべてのディレクティブに対してfieldIDsのインスタンスを変更できます。これにより、skipExecutionはIDごとに細かく行えるようになります。スタック内の後続ディレクティブすべてのfieldIDsからIDを削除するだけです。
パイプラインは次のようになります:
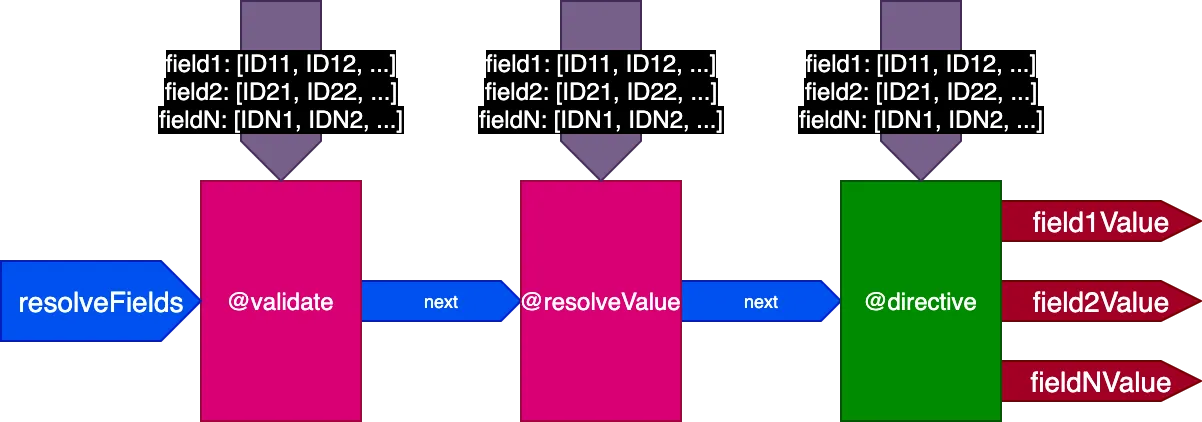
前の例に適用すると、2件のレコードを翻訳する最初のクエリを実行する場合、パイプラインは次のようになります:
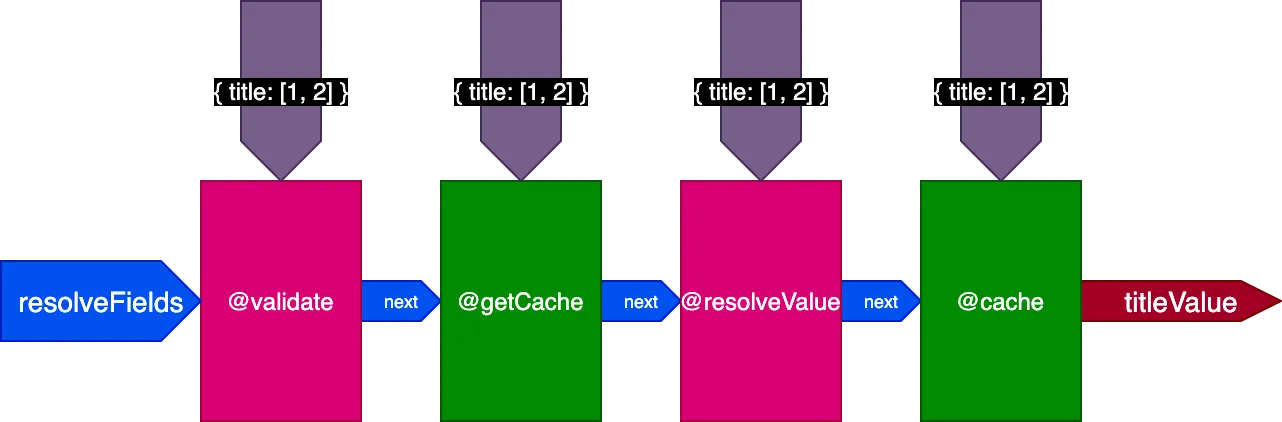
4件のレコードを翻訳する2回目のクエリを実行する場合、ディレクティブ@getCacheは4件のレコードすべてのIDを受け取りますが、@resolveValueAndMergeと@cacheはキャッシュされていない最後の2件のレコードのIDのみを受け取ります:
すべてをまとめる
これがディレクティブパイプラインの最終設計です:
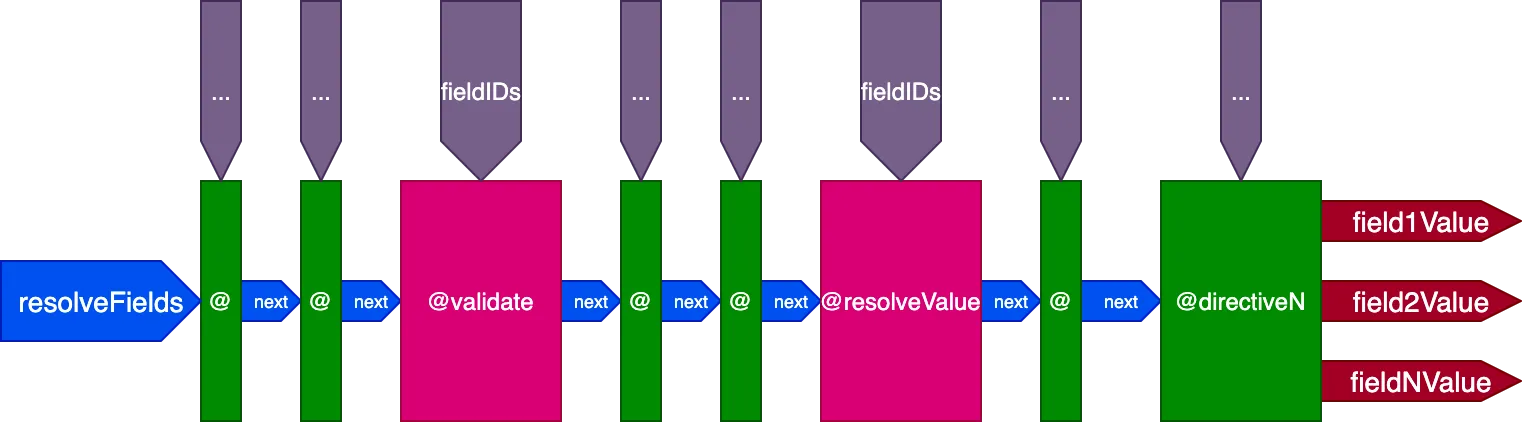
まとめると、その特徴は次のとおりです:
- フィールドリゾルバーはディレクティブパイプライン内から、ディレクティブ
@validateと@resolveValueAndMergeを通じて呼び出されます - ディレクティブは5つのスロットのいずれかに配置できます:
"beginning"、"before-validate"、"middle"、"after-validate"、"end" - ディレクティブは単一の呼び出しで複数のフィールドを解決します
- 単一のパイプラインにクエリに関与するすべてのディレクティブが含まれます
- 各ディレクティブは変数
fieldIDsを通じて、フィールドごとに解決すべきIDの独自のセットを受け取ります - ディレクティブはパイプライン内の後のステージのすべてのディレクティブに対して変数
fieldIDsを変更できます